Diffusion Based Encryption to Decrease Key Length Prediction in the Kasiski Method
by AhaanSinha-2 in Workshop > Science
256 Views, 2 Favorites, 0 Comments
Diffusion Based Encryption to Decrease Key Length Prediction in the Kasiski Method

The world of Cybersecurity may seem like a daunting one, however cybersecurity plays an increasingly important role in the online world today. In 2022 alone, there were over 4,000 data breaches with more than 22 billion records getting publicly exposed. This increase in vulnerability in systems is caused in large part due to the increasing influence of machine learning technologies. Due to the threat that machine learning based decryption provides, it has become even more vital to find a viable solution to such problems. Strong encryption methods such as asymmetric encryption have been able to combat this by providing an extra layer of security by using separate keys to encrypt and decrypt data. However it takes more processing time and resources. Symmetric encryption however has the opposite benefits providing a fast encryption and decryption time but lacks that same level of complexity.
So the question arises, how can we take both the benefits of asymmetric encryption and symmetric encryption to create an encryption algorithm that can achieve both a heightened level of complexity in a reasonable processing time. However to understand the solution we must first understand the problem at hand, mainly being how these decryption algorithms are able to decipher such encryptions. To understand this we must examine a vital part of the encryption process, the creation of a key. All of today's encryptions run on something called a public or private encryption key. These keys can be seen as the information given that a cipher will use to encrypt the plain text data. Decryption methods utilize key length for decryption which is the number of bits in a key. If a decryption system predicts key length it allows a threat actor to more efficiently narrow down and brute force a key which allows you to reverse the cipher text into a plain text message. Asymmetric encryption methods are able to resist such methods due to the use of 2 separate keys. However symmetric encryption or the use of the same key although having a faster processing time with less resources is prone to such decryptions. One common method of decryption widely used today goes by the name of the Kasiski Method. It works by looking through repeating phrases of 3 letters or more in the cipher text and taking the difference between each repetition. This difference is a multiple of the key length which can narrow down possible key lengths. I then found an encryption process called diffusion. This principle works by spreading the repetitions and preventing the occurrence of more repetitions. Using this knowledge I wanted to test whether the principle of diffusion could decrease the accuracy of these machine learning assisted attacks in symmetric encryption algorithms.
However before starting the experiment I wanted to know what type of cipher I could use to test against kasiski’s method. To test the effect of diffusion in the confines of this experiment I decided to use the hill cipher as my type of symmetric encryption as it is something called a polygraphic substitution cipher which is the primary focus of the Kasiski Method or our decryption method we are using in this experiment. But first to understand how we are going to code the kasiski method we have to understand how the Hill Cipher encrypts the data by using a given key. Say we are given a key and a piece of cipher text which we then convert into the form of numbers with 0 corresponding to a and 25 corresponding to z. We then take our converted plaintext and then a key matrix as shown below. After we have done this we must split the converted plaintext based on the size of the key matrix.We can then multiply the values of each matrix with each other and mod 26 it as shown in this picture here.
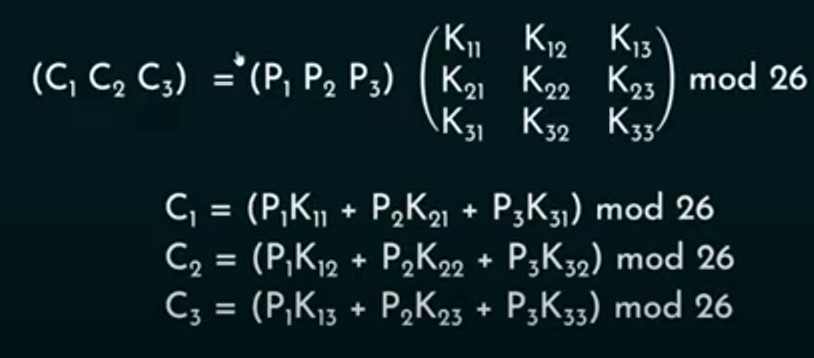
After we have done this we now have our hill cipher created encryption which we can encrypt for each segment of our plaintext until it is now encrypted.
Collecting the Data
Now that we understand how to encrypt data using the hill cipher we can start creating a data set of plaintext and keys that we can experiment with throughout our experiment. In the case of this experiment I decided to create keys of 5 different key lengths from 2 by 2 to 6 by 6. I created a 1000 different plaintexts and 100 different keys with 20 different keys for each different key length. In the excel sheet shown below there are around 20 data points shown with the plaintext being taken from passages of Harry Potter the Sorcerer’s Secret with newly generated keys.

Now that we have all our data points we must now apply our hill cipher to each point. To do this we must first import the data in our excel file and input it into python. To do this we must use the pandas functionality like this to access all the data in the files. In the case of this experiment I decided to split my data based on each key length subgroup and converted each to cipher text seperately.

Creating the Hill Cipher Functionality
Next we need to create the first step of the Hill Cipher functionality. First we need to create a method which can transform the string key we input into a key matrix format with each of the letters converted into numbers. We then have to multiply our plain text and our new key matrix. However to do this we have to convert our string based plain text into an array of integera that we can multiply by the key matrix. Then we multiply the array based result which we will then convert back to a string format giving us our encrypted cipher text.
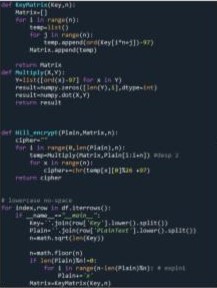
The Kasiski Method
Finally after we do this we have all our encrypted cipher text. Now that we have our cipher text our next step is to test them with the machine learning assisted kasiski method algorithm. We can do this by taking our csv file and inputting it into our kasiski method program which works by converting the letters into an array and finding phrases of 3 or more and categorizing them as repetition. It then takes the differences of these repetitions and creates possible key lengths based on the number of repetitions and the length between each repetition.
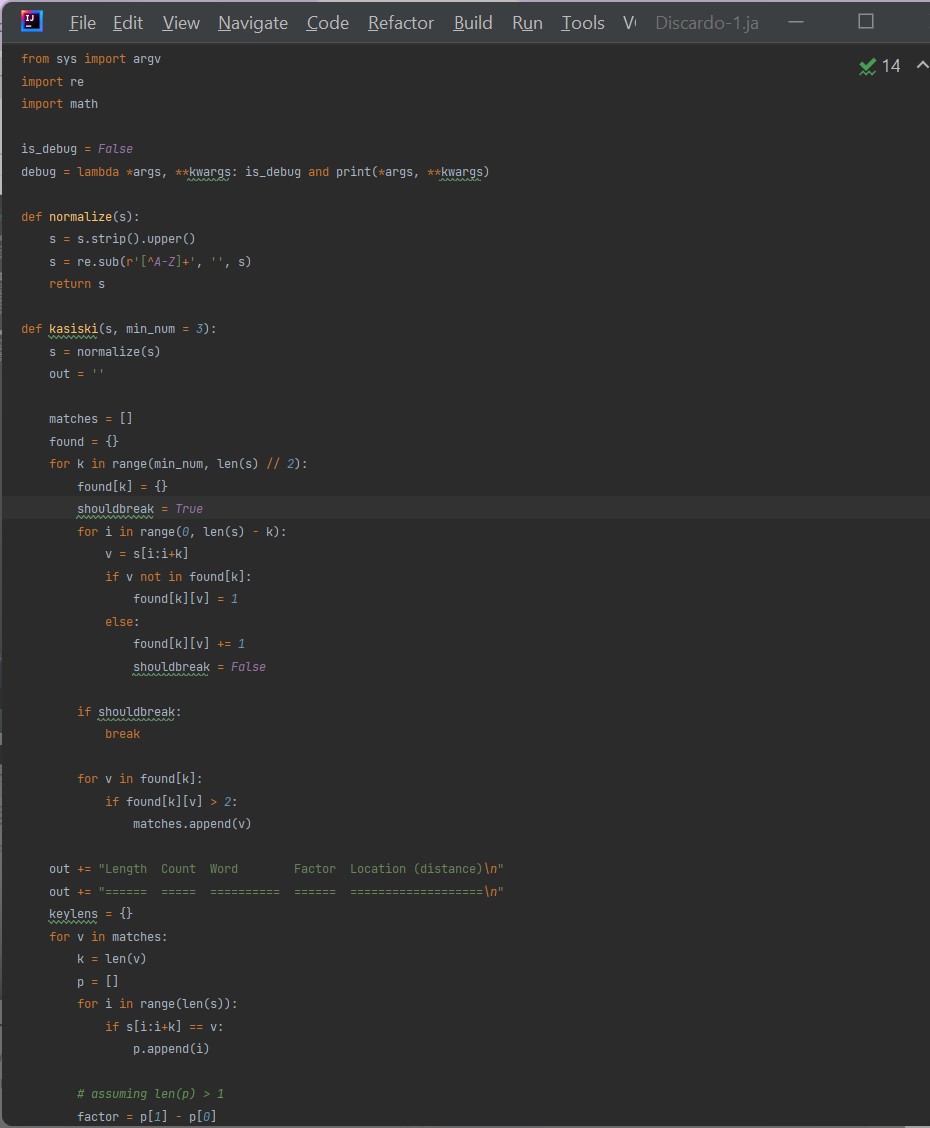
Once I ended up getting my encryption I ran one set of the thousand encrypted data points without diffusion while recording whether or not it accurately predicted the key length and I tested the diffusion based encryption where I again tested for the accuracy of the kasiski method.
Results
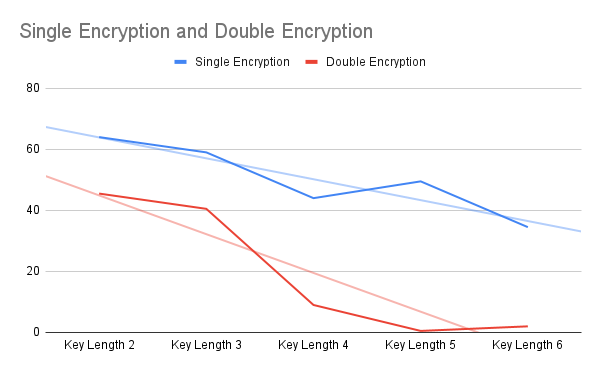
Based on the results of my experiment the encryption that utilized the principle of diffusion had a 19.5 percent accuracy while a standard hill cipher encryption without diffusion had a 50.2 percent accuracy showing that the principle of diffusion is much more equipped to handle against key length decryption methods. I also noticed that the double encryption accuracy reached a drastic decrease in accuracy from key lengths 4 through 6 meaning that as the encryptions would be more complex the principle of diffusion would be more effective and decreasing accuracy as compared to encryptions that did not utilize the principle of diffusion as shown in the graph below.
Although I knew that there was a large decrease in accuracy I wanted to see whether I could conserve the processing time. To track the amount of time the program took with the principle of diffusion and without, I utilized a library that could track the processing time taken by the program for each level of encryption as shown in the picture below.

Using this we were able to calculate the processing time with the principle of diffusion as 1.77 seconds and the processing time without the principle of diffusion is .98 seconds. This means there is a 1.8 times difference between the processing time of diffusion based encryption and non diffusion based encryption but a 2.5 times difference in security. That means the overall security to processing time ratio is more for the principle of diffusion meaning it provides more security at a reasonable processing time.
I believe the results of my experiment bring to light a concept that can allow an average user or a large company the ability to encrypt large amounts of data at a more efficient rate while maintaining a higher level of encryption than symmetric encryption while maintaining a faster processing time than asymmetric encryption.